Kafka — Elastic Search Integration — A Novice way
This is going to be very interesting for folks who are interested to connect Kafka directly to the Elastic Search. As the architecture team in the organization, we wanted to bring agility and robustness to how we ingest data today. We are totally dependent on AWS services at this moment and one of the many reasons is that we did not want to have a high dependency on one cloud provider and wanted a solution to be portable.
After long deliberation, I thought of doing the proof-of-concept on ingesting data from Kafka to elastic search. However, I got into a lot of trouble sorting this out as there was no clear article or documentation present anywhere which shows the right steps to perform. Most of the code on GitHub was not working or they weren’t complete at all or outdated and this was a huge challenge for me to quickly bring this up and running for my team.
In this article, I thought to pen down my learning with complete implementation so the folks need not see a lot of content and struggle :).. so let’s begin...
Prerequisites :
- Should have a Linux or Mac machine
- Should have installed docker desktop and docker-compose
- Should have a minimum of 6GB of memory & 1.5GB Swap space in docker resources

Code & Configurations can be downloaded from below:
https://github.com/pandasm/kafka-elasticsearch-onprem
Step 1: Setup Kafka & Elastic Search in the machine
We will be using docker containers to run our Kafka and elastic search instance on the local. In the subsequent articles i will also show how you can use Helm charts to deploy the containers on Kubernetes and also manage volumes.
There are a lot of content on the internet with various ways to create your docker-compose file and it only adds confusion as to which one we need to use. To avoid the confusion I have uploaded all the artefacts to the GitHub link above which you can use to bring the environment up and running.
Let’s go through the docker-compose file components and see what each component will do for us:
Note: You need to map the volumes to the appropriate folder on the machine where you are running this docker-compose file.
1. Apache Zookeeper: This component is used in the distributed systems to synchronize the services and as a naming registry. When used with Kafka, Zookeeper will track the status of the nodes in the Kafka cluster and maintain a list of Kafka topics, messages, and partitions.
2. Apache Kafka: This is an open-source distributed event streaming platform to implement high-performance data pipelines, streaming analytics. It is based on a publisher-subscriber model to provide a durable messaging system. Event data will be published in the Kafka topic and the consumer will consume the events data and perform processing. The data is stored in the form of a record which are nothing but byte arrays that can store any object in any format. A record has four attributes — key and value are mandatory but other than that timestamp and headers are optional.
Kafka has 4 parts, they are :
— Broker: It handles all the requests from the producer, consumer, and metadata and keeps data replicated within the cluster.
— Zookeeper: It keeps the state of the cluster which is the broker, topics, users, messages, partitions, etc.
— Producer: It sends records to a broker
— Consumer: It consumes record in batches from the broker
3. Schema-registry: The consumers use the schema to deserialize the data. The Kafka schema registry enables Kafka clients to read and write the messages in the well-defined and an agreed schema. Thus enforcing the compatibility rules between the producers and the consumers.
4. KSQL-server: It is a SQL engine that sits over Apache Kafka to build streaming applications. It features being distributed, scalable, reliable, and real-time. It supports a wide range of streaming operations like data filtering, transformations, aggregations, joins, windowing and sessionization.
5. KSQL-CLI: It is a command-line interface to connect to the KSQL database. You can run the KSQL queries similar to the ones offered in the SQL databases. KSQL can read the data in JSON or AVRO. You can skip KSQL CLI if you do not want to write the queries for Kafka.
6. Kafka Connect: This is a connector service that we will use to connect to Elastic Search. Predominantly its job is to scalably and reliably streaming data between Kafka and the other data systems. This is a simple and the easiest way to move data out of Kafka. The platform ships with several built-in connectors that can be used to stream data to the relational database or Elastic search or S3 etc.
7. Control Center: It is a web-based tool for managing and monitoring Apache Kafka. It provides the interface that allows the developers and operators to quickly understand the health of the cluster, control the messages, topics, and schema registry and run and develop KSQL DB queries. In our example, you can connect to the control center by clicking on http://localhost:9021
8. Rest-Proxy: It provides a restful interface to the Kafka cluster making it easier to publish and consume the messages, also view the state of the cluster, and perform administrative actions without using the native Kafka protocols and clients (native libraries)
9. Elastic Search: It is used to store, search and analyze a huge volume of data quickly and in the near real-time and provide a response in milliseconds. It can achieve a fast response because rather than search the text directly it searches an index. We are going to use Elastic Search to ingest data from Kafka.
Now run the docker-compose file (refer to the below screenshot)


After you check that the containers are running you can then check if the cluster is running.

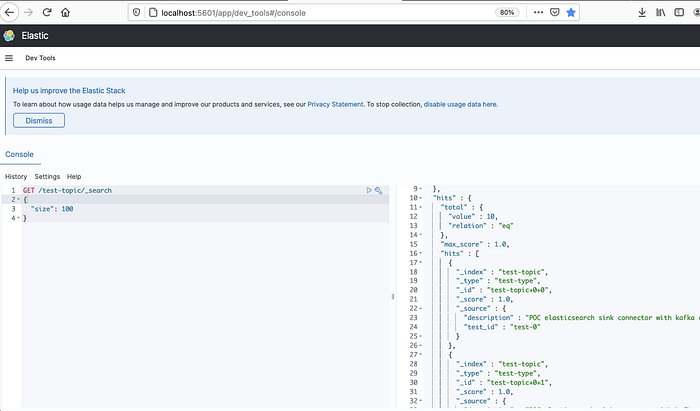
Step 2: Create the index in Elastic Search
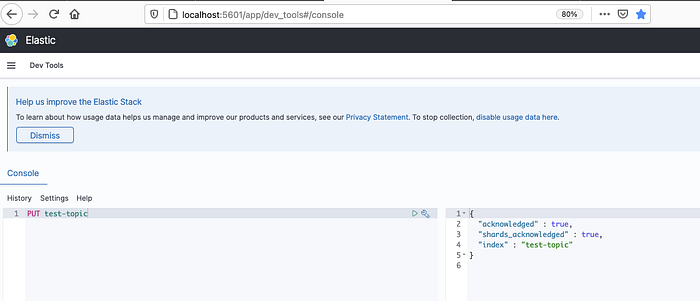
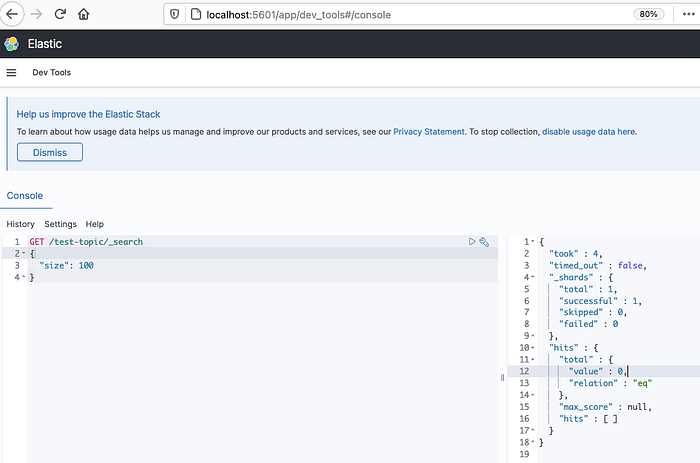
Open Kibana using the url http://localhost:5601/app/dev_tools#/console and then create an index (1) . Once the index is created you can query the index (2)
Step 3: Create a connector in Kafka
The sink connector that you will define in Kafka requires a source topic and the destination (Elastic Search). You can send a post request as below to Kafka. This will create a topic and also creates a consumer with the subscription on the defined topic. You can use postman or any other rest client to fire the payload onto Kafka broker.
Note: You can refer the refer the postman collection in the GIT location.
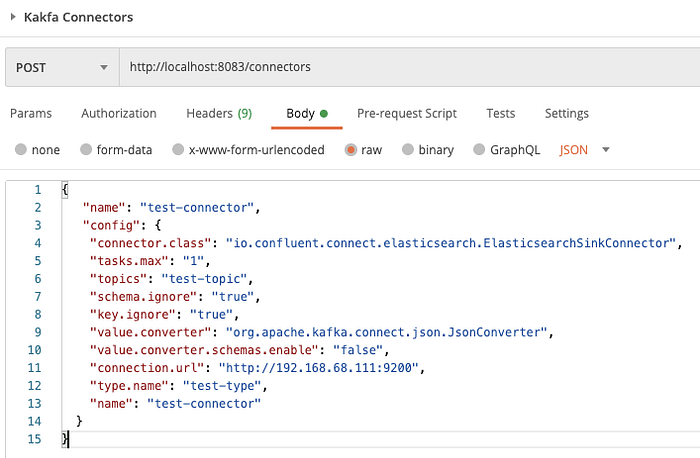
Name : Represent name of the connector
Connector class: Represents the sink connector (this will consume the topic messages and ingest in the elastic search index)
Topic: Represents the topic name which sources the data to the connector
Schema & Key Ignore: Represent ignoring the schema and the key in the message (that mean there is no fixed schema that needs to be presented and verified)
Value Converter : The object that is being read by the connector will be converted to the JSON (default message type of Kafka is Avro)
Connection url : Represents the elastic search ip and port at which the connector will send the data (topic name should match the index name)
Response received as :
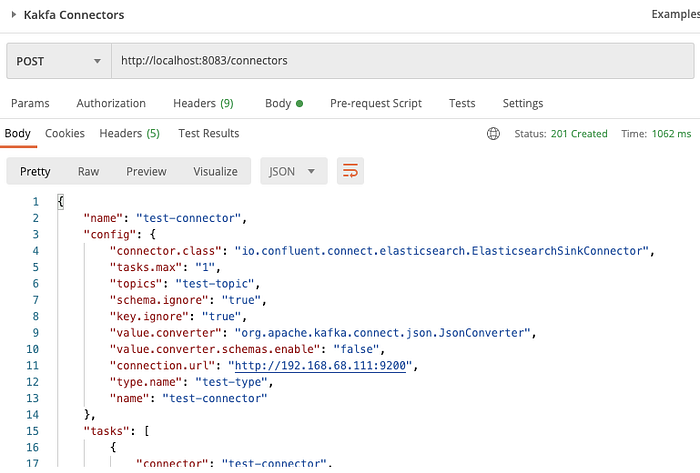

Once this is done you can now see in the control center of Kafka that a topic has been created as shown below (if the topic is already present and you are running the connector service will only create a consume to start listening to the topic)
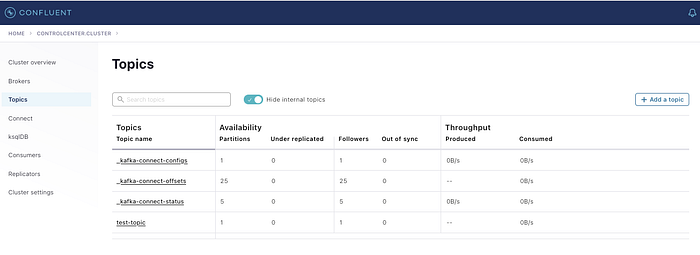
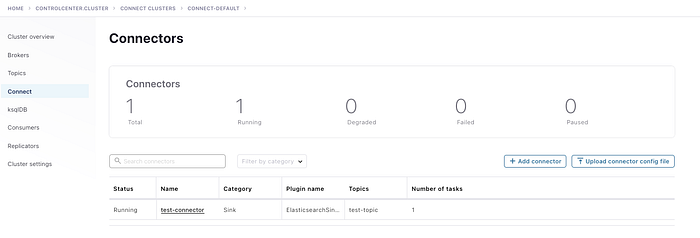
When you will click on the connect section, you will see that a sink connector is running. If you further click on the name and go to the settings then you will see that the configurations that you have posted through a rest client will be present in the respective fields. You can attempt to do this manually if you do not want to use the rest client.
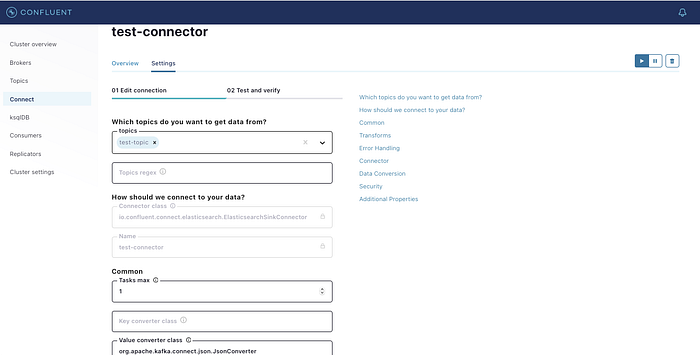
Step 4: Write the code in Python to publish to the topic
This code is quite interesting as the code to publish and subscribe especially over REST has not been either discussed or written well in any of the articles that I have seen on the internet and it has been fantastic for me to actually read the Kafka documentation to implement the rest subscriber method.
If you see the code, I have implemented both ways that are using the native Kafka libraries and the REST way (you can use whichever way is comfortable with you). The program is pushing some messages to the Kafka topic and the same should be appearing at the Elastic Search index
Note: You can refer the refer the code in the GIT location (onprem.py). The code will publish some messages with varying test ids.
The Publisher / Producer
- Using Kafka Libraries
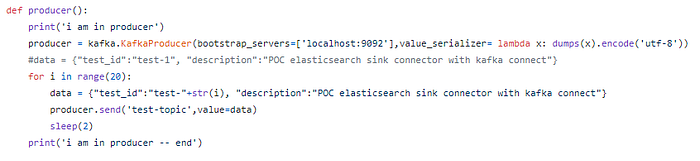
Bootstrap server: Where Kafka is listening to the messages (check Kafka configurations in docker-compose for reference)
str(i) — It is nothing but sending a unique test id so that unique messages are seen in elastic search.
- Using Rest

The important thing to remember here is to put the right header values and also wrapping the JSON object with a records JSON array. Kafka always reads and stores data in records and hence the JSON needs to be wrapped.
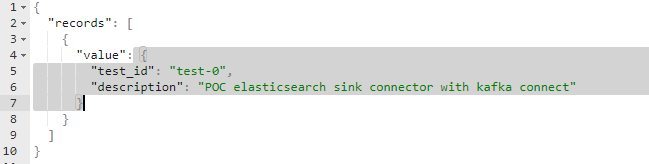
If you are sending JSON (seen in the example) you need to make sure that the content type is JSON. Secondly while defining your connector you need to specify the converter as JSON and thirdly while defining the docker-compose for Kafka-connect the key and value converter should be defined as JSON. Similarly, if you want to send and consume Avro data you can change the value to Avro.
Since the code is written in python we have a written requests library to make the rest calls. We are sending the data to 8082 but if you want to change the port then you need to change in the docker-compose file -> rest proxy section and change the port value of Kafka listener.
Code Execution — Publishing the messages
Once you run the code (1) you will see the messages are apprearing on the topic (2) when you click on the message section. Consumer will show that there are some messages behind (this is reading from the topic and pushing it to the elastic search) (3). Once the messages are completed read the counter is set to 0 (4). Elastic Search shows that the messages are being ingested from Kafka to Elastic Search (5)

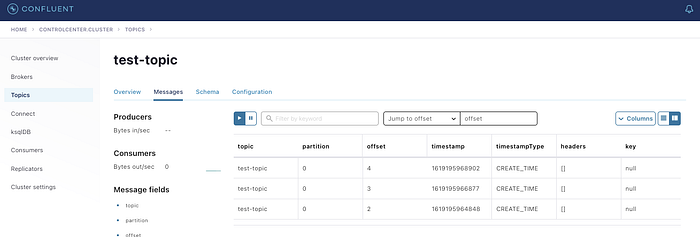
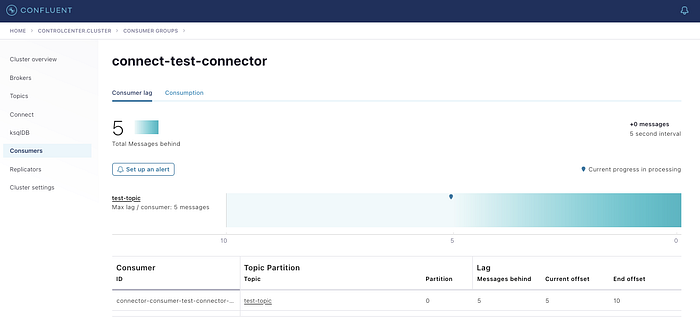
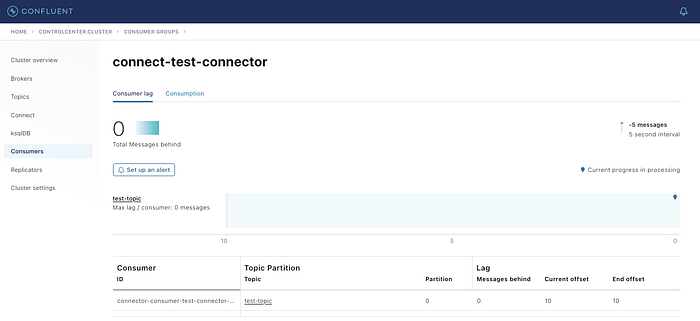
Though I have published both the publisher and subscriber code, still in the next article I will be explaining how to subscribe to the messages from Kafka Topic. It is important to know the entire thing works…
You can read the Kafka Subscription article HERE.
If you find this article interesting or having difficulty in doing the setup, please feel free to reach out to me on Linked-in In or Twitter and DM me your questions.
